
WP 2 Perception and Action
Project partners contributions
Input Processing Tool (OFAI)
Natural Language Input Processing Tool. The tool was conceived as a robust mechanism for constructing a rich annotation of natural language text. It integrates an extensive set of NLP components and resources with the ontologies and databases created for and used in the Rascalli platform. The tool structures a natural language text using a finite set of categories and symbols, and creates a computer interpretable representation of human utterances. In this process, the tool incorporates knowledge about various concepts and relations (utterance categories, question categories, POS tags, WordNet relations, role of words in an utterance such as question focus or question interest, mapping between words from a user utterance to available ontologies and database categories).
Natural Language Database Interface (OFAI)
For the first versions of the Rascalli system, OFAI developed a natural
language query interface to retrieve information from the music databases
available to the Rascalli agents. The tool analyses the parse tree of a
question and maps it to concepts and relations stored in the databases. If the
mapping is successful, a query is formulated and executed.
Question Answering System (OFAI)
Internet Based Open Domain Question Answering System. The processing stages of the tool include: question analysis, accessing the Internet resources, and analysing the accessed documents. The tool, amongst others, incorporates a number of natural language processing tools (named entity recognition, part-of-speech tagger, chunker, stemmer, etc.), information retrieval tools (document indexing and querying engine) and machine learning based classifiers and clustering solutions. It further includes: SVM based question classification, keyword extraction, keyword scoring, and query generation modules. A set of tools usable to access a variety of Internet websites such as wikipedia.com, dictionary.com, howstuffworks.com, wordnet.org., and the Internet search engines such as Google, Yahoo, Altavista posses the capabilities to interpret the results of Internet resources (e.g. extract distinct definitions for a given term, report on ambiguity of a used term or possible misspellings, provide information on the number of available documents for a given query, distinct senses for a given term, the lack of term related documents or of a searched definition). The tools used to analyse the retrieved documents include: text segmentation, document scoring and indexing, a local search engine (using: Lemur Indri), the Fine Grained Answer Candidates Extraction module (employing a combination of: LingPipe NER, Gazeeteers, and extraction rules).
RSS Feed Tool (OFAI)
RSS feeds provide a mechanisms for Rascalli agents to detect changes in their
environment. While technically RSS feeds have to be polled and retrieved (and
thus obtaining information from an RSS feed is an active behaviour), they can be easily modelled within the Rascalli system to be part of a dynamic
and changing environment,with new feed items arriving in a manner that is temporally
unpredictable for the agent. Thus we implement a RSS feed tool which
continuously (i.e. in very short intervals) polls and
retrieves feeds that have been registered by a Rascalli agent without requiring
any further activation. As soon as new
data is retrieved, the tool triggers a signal which is perceived by the
Rascalli agent.
The RSS feed tool includes a mechanism to filter news feeds for sets of
keywords, allowing Rascalli to be informed only of news containing sucessful
matches.
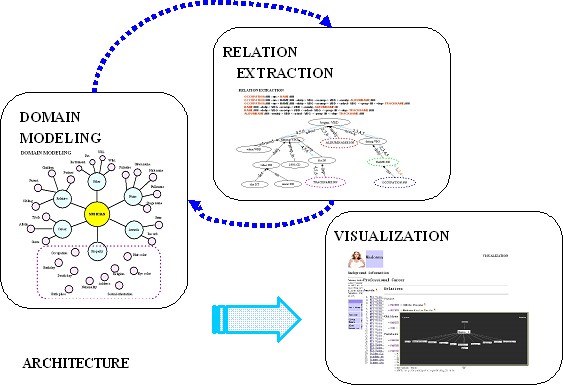
Domain Modelling, Information Extraction and Visualization (DFKI)
DFKI has continued the research and implementation work, namely,
applying NLPs to relation extraction. The major task is the development
of an
NLP-based information acquisition service platform, which can retrieve
and extract musician relevant information from interesting web sites,
utilizing IR, ontology and NLP tools and allows an easy access to the
acquired information. The information acquisition service platform
consists of three components:
domain modelling: it defines the relevant concepts and
their relations of the musician profiles and the associated gossip
information. The concepts and their relations are structured in an
ontology.
relation extraction: it identifies the relevant concepts
and detects relations among different concepts;
visualization: it enables users to access the acquired
data via different options, such as, ontology-driven hierarchical
navigation and question answering.
The interaction among the three components is depicted in the following
figure:
Internet-based Perception: Information Discovery via Information
Wrapping and Information Extraction (DFKI)
DFKI has worked on automatic and semi-automatic acquisition of data
from web, in order to collect sufficient information and knowledge
about musicians, in particular, the personal profiles and other gossip
information. The methods developed for this workpackage contribute to
the perception, while the acquired knowledge supports the actions of
agents. We apply both information wrapping and information extraction
and information merging techniques. The whole discovery is embedded in
a bootstrapping framework, namely, starting with some examples and then
learning more and more information after several iterations.
Information Wrapping: Data Collection from Structured or
Semi-Structured Web Portals: This process aims to extract data from
websites where the gossip information about musicians are described,
e.g., the community site Wikipedia
and the special web portal for people and their profile NNDB.
It starts with a set of musicians provided by the consontrium partner
as seed . An extra data cleaning method is developed to
filter the noisy information contained in the seed content. The
data extractor component applies the information wrapping
techniques by sending query about an artist from the seed set to the
websites and map the extracted relevant pieces of information to the
RASCALLI gossip data types. The information merging
component merges the data discovered by various sources and validate
them in some degree and store them in the gossip database. The
bootstrapping will be triggered, if new musicians are discovered. The
new person lists will be used as new seed again.
Information Extraction: Relation
Extraction from Unstructured Free Texts: This process aims to
extract musicians and properties of the musicians and recoginze and
classify the corresponding relation types. We applied named entity
recognation and dependency parsing to the unstructured free texts. We
have automatically crawed relevant web articles reporting on news
about musicians and ranked them according to occurrences of the
musicians.The miminally supervised machine learning method DARE took
the known musician list and relations won by the information wrapping
method and extract more and more relations in a bootstrapping manner.
Visual Browser(DFKI)
DFKI has developed the visual browser to allow users the access to
the
RASCALLI information. The visual browser tool was originally developed
in the dropping knowledge
project.
We have modified it and adapted it to the RASCALLI needs. The visual
browser takes a taxonomy or even an ontology in OWL as input. Users
can navigate the concept hierarchy in a very fancy and convenient way.
Furthermore, each conept node in the visual browser is associated
with information services
which provide additional information about the concept, such as, search
in WIKIPEDIA, search in Google, search in RASCALLI musician data. The
terminal
nodes in the visual browser graph are the musicians.
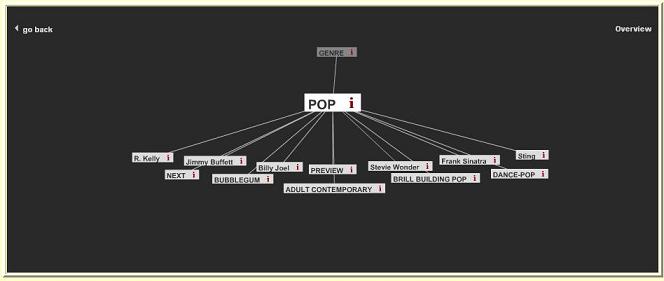
We provide not only the facts about a musician and also a network
view of people related to them.
NLP Tools for Applications (DFKI)
DFKI has prepared severval relevant NLP tools for the consortium.
They include SProUT sysetm for the named
entity recognition and the Java interface of MINIPAR for
the dependency parsing. We also experimented with the Stanford Parser and tools provided by OpenNLP.
Back to workpackages
RASCALLI is supported by the European Commission Cognitive Systems
Programme (IST-27596-2004).
RASCALLI develops a new type of personalized cognitive agents, the
Rascalli, that live and learn on the Internet.
Rascalli
combine Internet-based perception, action, reasoning, learning, and
communication.
Rascalli come into existence by creation
through the user. The users not only create their Rascalli but also
train them to fulfil specific tasks, such as be experts in a quiz
game or assist the user in a music portal.
![]()