OFAI Multi-Modal Task Description (MMTD) Corpus
A collection of four task-oriented datasets comprising audio (German), video and multimodal annotations
Publications
Details about the full data set and how the data was collected can be found in Stephanie Gross & Brigitte Krenn: The OFAI Multimodal Task Description Corpus. LREC 2016.
Authors
Licence

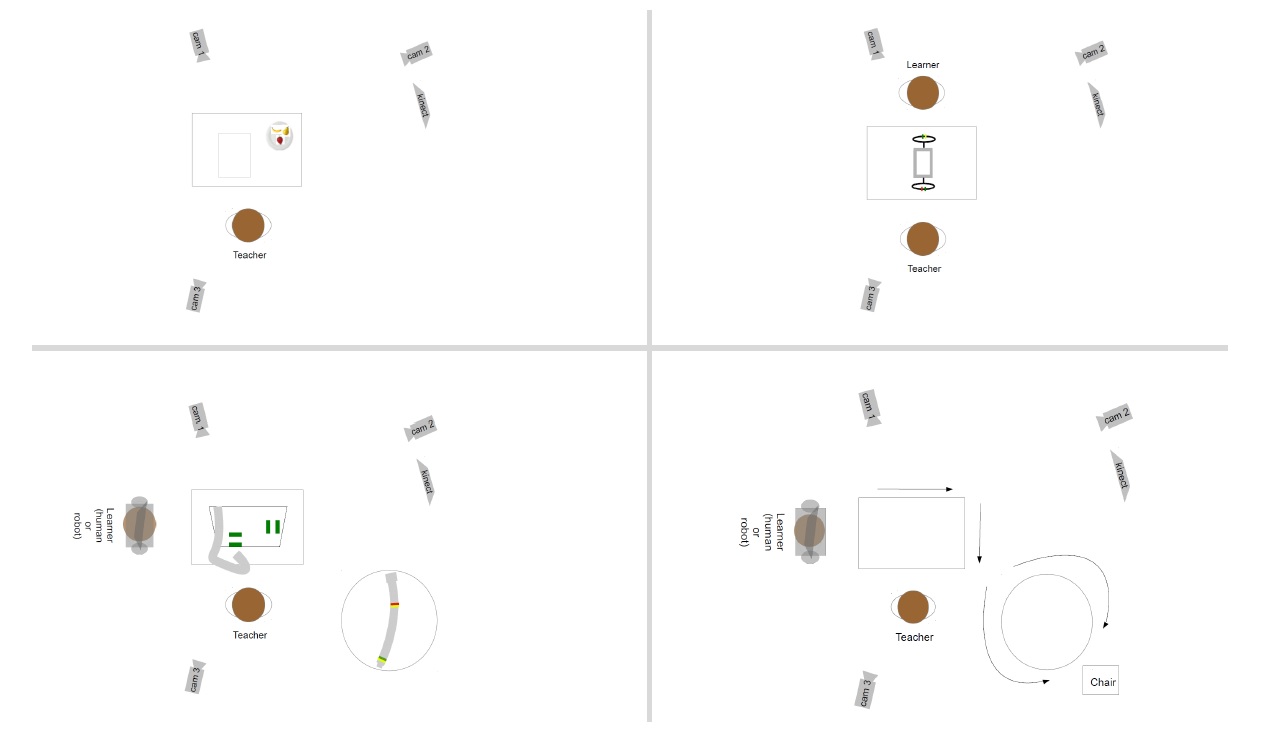
Key facts
- Version
1.0 - Release date
13 May 2016 - Language
German - Modalities
Audio, Video, Multimodal Annotations - Licence
CC BY-SA-NC 4.0 - Contact
Stephanie Gross