|

Labeling
The islands themselves might not be a very satisfying user interface. Although clusters can be identified, without further information it is not possible to understand what determines the cluster. It is desirable to have a summary for each cluster describing its main characteristics and thus explaining why the map is structured the way it is.
The island visualization can easily be combined with any labeling method. For example, the islands can be labeled with the song identifiers. On the other hand these identifiers, when assuming that the songs are unknown to the user, do not help the user understand the clusters.
There are several methods of labeling SOMs such as the LabelSOM technique or the technique used for the WebSOM project. Both techniques have been developed especially for the domain of text archives, however, they can be applied in a more general context. The LabelSOM technique uses the mean value and the variance of an attribute within a cluster to decide if it is a good description or not. The WebSOM technique compares the mean values of the attributes within a cluster with those of other clusters and finds descriptors, which characterize some outstanding property of a cluster in relation to the rest of the collection. Other techniques include inductive machine learning algorithms, which extract fuzzy rules to describe the clusters.
All these techniques have in common that they find descriptions based on the dimensions and their meanings. For example, in the domain of text archive analysis it is common to use the vector space model, where the text documents are represented in a high-dimensional space, with each dimension assigned to some word. The labeling techniques try to find the most descriptive dimensions (i.e. words) and use these to describe the map.
This cannot be applied directly to the music collection and the methods introduced in this thesis since the single dimensions of the 1200-dimensional modified fluctuation strength vectors are rather meaningless. For example, the MFS value at the modulation of 2.4Hz and bark 4 would not be very useful describing a specific type of music.
Since the single dimensions are not very informative aggregated attributes can be formed from these and can be used to summarize characteristics of the clusters. There are several possibilities to form aggregated attributes, for example, using the sum, mean, or median of all or only a subset of the dimensions. Furthermore, it is possible to compare different subsets to each other. In the following 4 aggregated attributes, which point out some of the possibilities, are presented. If the user understands the MFS it is possible that the user directly creates the aggregated attributes depending on personal preferences.
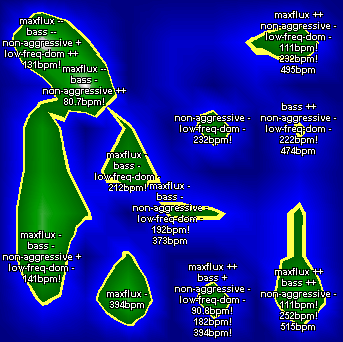
The used aggregated attributes are Maximum Fluctuation Strength, Bass, Non-Aggressive, and Low Frequencies Dominant. The names have been chosen to indicate what they describe. Details on each of them can be found in the thesis.
Other interesting aspects of the MFS include the vertical lines that correspond to beats at specific frequencies. To extract information on these a simple heuristic can be used to find significant beats. First the sum over all critical-bands for each modulation frequency of the MFS are calculated and normalized by the maximum value so that the highest value equals one. High peeks correspond to significant beats and are found using the following rules. (1) All peeks below 43% of the maximum are ignored. (2) All other peeks need to be at least 12% higher then the closest preceding and the closest succeeding minima. (3) Finally from the remaining peeks only those are selected which are higher then any other remaining peek within the modulation frequency range of 1Hz.
The island visualization can easily be combined with any labeling method. For example, the islands can be labeled with the song identifiers. On the other hand these identifiers, when assuming that the songs are unknown to the user, do not help the user understand the clusters.
There are several methods of labeling SOMs such as the LabelSOM technique or the technique used for the WebSOM project. Both techniques have been developed especially for the domain of text archives, however, they can be applied in a more general context. The LabelSOM technique uses the mean value and the variance of an attribute within a cluster to decide if it is a good description or not. The WebSOM technique compares the mean values of the attributes within a cluster with those of other clusters and finds descriptors, which characterize some outstanding property of a cluster in relation to the rest of the collection. Other techniques include inductive machine learning algorithms, which extract fuzzy rules to describe the clusters.
All these techniques have in common that they find descriptions based on the dimensions and their meanings. For example, in the domain of text archive analysis it is common to use the vector space model, where the text documents are represented in a high-dimensional space, with each dimension assigned to some word. The labeling techniques try to find the most descriptive dimensions (i.e. words) and use these to describe the map.
This cannot be applied directly to the music collection and the methods introduced in this thesis since the single dimensions of the 1200-dimensional modified fluctuation strength vectors are rather meaningless. For example, the MFS value at the modulation of 2.4Hz and bark 4 would not be very useful describing a specific type of music.
Since the single dimensions are not very informative aggregated attributes can be formed from these and can be used to summarize characteristics of the clusters. There are several possibilities to form aggregated attributes, for example, using the sum, mean, or median of all or only a subset of the dimensions. Furthermore, it is possible to compare different subsets to each other. In the following 4 aggregated attributes, which point out some of the possibilities, are presented. If the user understands the MFS it is possible that the user directly creates the aggregated attributes depending on personal preferences.
The used aggregated attributes are Maximum Fluctuation Strength, Bass, Non-Aggressive, and Low Frequencies Dominant. The names have been chosen to indicate what they describe. Details on each of them can be found in the thesis.
Other interesting aspects of the MFS include the vertical lines that correspond to beats at specific frequencies. To extract information on these a simple heuristic can be used to find significant beats. First the sum over all critical-bands for each modulation frequency of the MFS are calculated and normalized by the maximum value so that the highest value equals one. High peeks correspond to significant beats and are found using the following rules. (1) All peeks below 43% of the maximum are ignored. (2) All other peeks need to be at least 12% higher then the closest preceding and the closest succeeding minima. (3) Finally from the remaining peeks only those are selected which are higher then any other remaining peek within the modulation frequency range of 1Hz.
|
| Figure 1: The visualization paramter is set to n=1. The mountains and hills are labeled with words describing the rhythmic properties of the music represented by them. |